Human-Centric, Fine-Grained Suite
A 10-dimension protocol covers cross-modal alignment, speech content/realism, and audio-video perceptual quality in realistic human scenes.
AVBench targets the core bottleneck of modern T2AV systems: existing metrics miss subtle but critical human-centric failures. We provide a fully automated, fine-grained, and human-aligned evaluation protocol with specialized evaluators and continuous confidence scores.
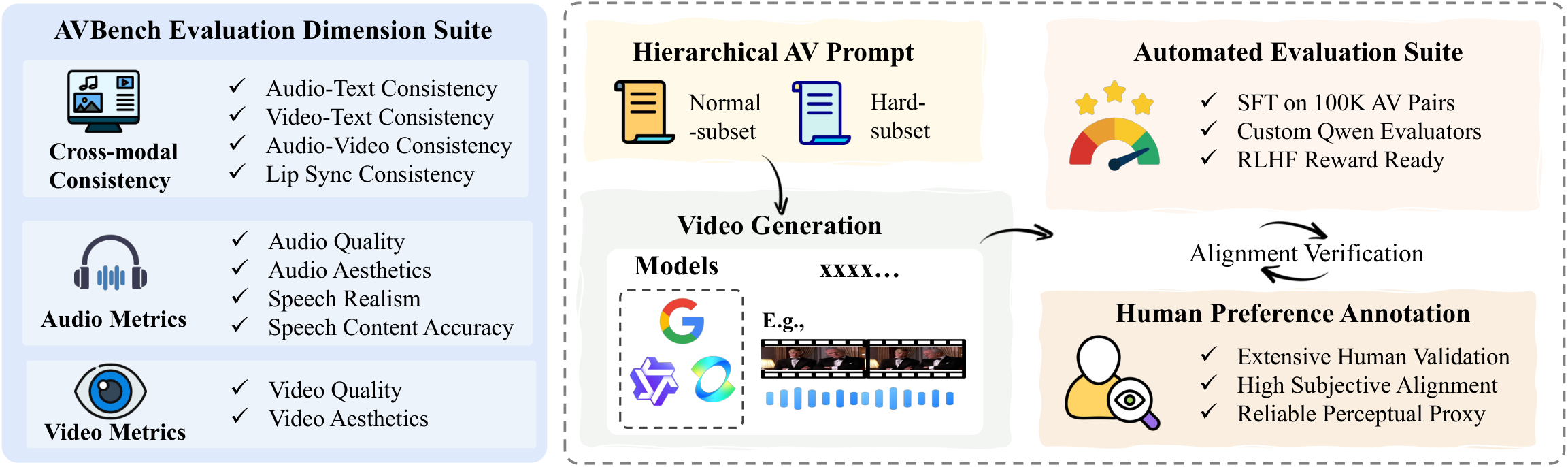
Figure 1. Overview of our AVBench. It integrates a multi-dimensional evaluation suite covering cross-modal consistency, audio metrics, and video metrics for human-centered real-world scenarios, together with a hierarchical AV prompt design containing normal and hard subsets. The framework supports automated large-scale assessment and human preference-based alignment verification to ensure reliable perceptual alignment.
Rapid advances in audio-video (AV) generation have enabled high-fidelity synthesis with synchronized sound, particularly for human-related scenarios involving speech and interactions. Yet evaluation for AV generation remains at an early stage, with only a few coarse-grained benchmarks for human-related scenarios and relying on limited preset evaluations with generic multimodal LLMs, leading to inaccurate assessments of model capabilities. To address these issues, we introduce AVBench, a fully automated benchmark tailored for human-centric AV generation. AVBench is built on two key designs for comprehensive and accurate evaluation: (i) Human-centric and fine-grained metrics. AVBench integrates ten evaluation dimensions designed for human-centered real-world scenarios, covering visual quality, audio quality, and multi-level consistency across modalities. These practical metrics capture human-related details that existing benchmarks often overlook.
(ii) Specialized evaluators via preference learning. To address the lack of specialized training data, we construct large-scale supervision by transforming real-world videos into diverse training pairs with controlled perturbations. After fine-tuning on this high-quality dataset, the evaluators learn to reliably detect subtle cross-modal inconsistencies. Crucially, instead of producing discrete textual judgment, AVBench derives continuous evaluation scores from the model's prediction confidence on binary decisions. This probabilistic scoring mechanism enables a more reliable assessment than traditional VQA-style evaluation and aligns closely with human judgment. Taken together, AVBench offers automated evaluation for AV generation, demonstrates strong potential for data filtering and serving as a differentiable reward signal for Reinforcement Learning from Human Feedback (RLHF).
Key visual summaries adapted from the paper to explain data curation, evaluator design, and model-level performance patterns.
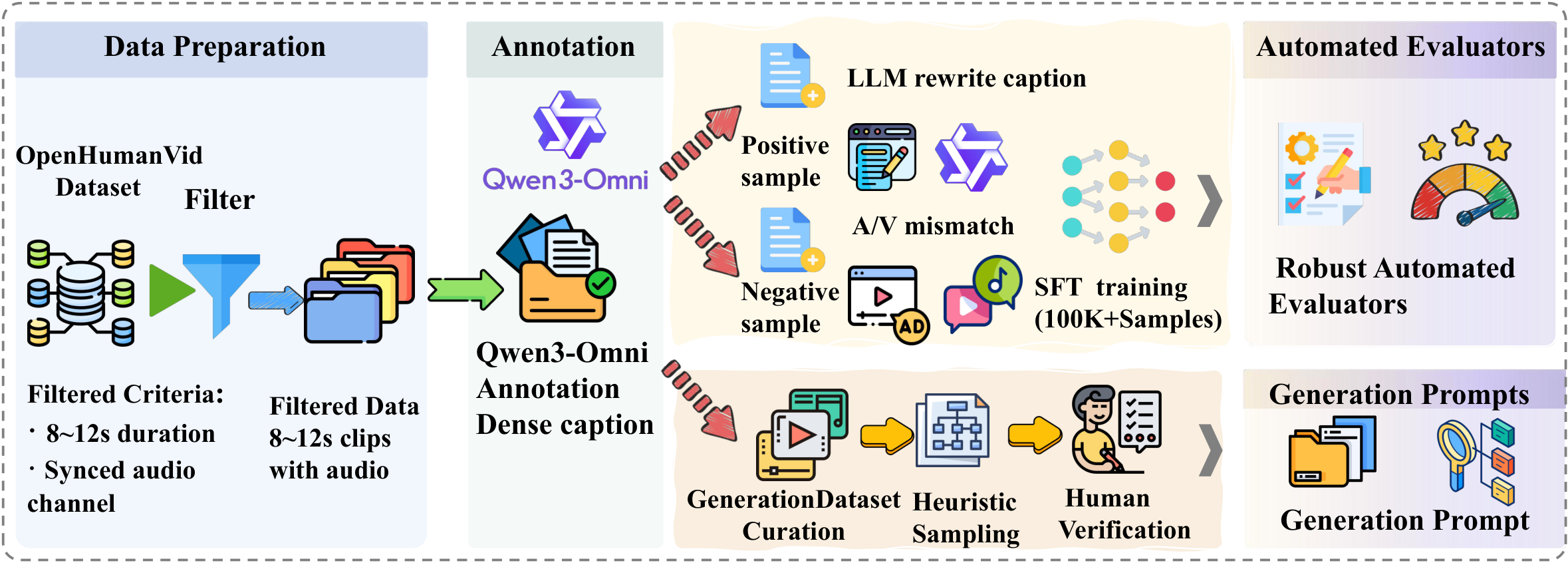
Figure 2. Overview of the AVBench construction pipeline. Our framework comprises two parallel workflows. The upper branch illustrates the training of the automated evaluators: clips are densely annotated and then branched into positive and hard-negative samples for SFT. The lower branch outlines benchmark prompt curation via heuristic sampling and strict filtering. Together, robust SFT evaluators and high-quality prompts form a fully automated evaluation framework.
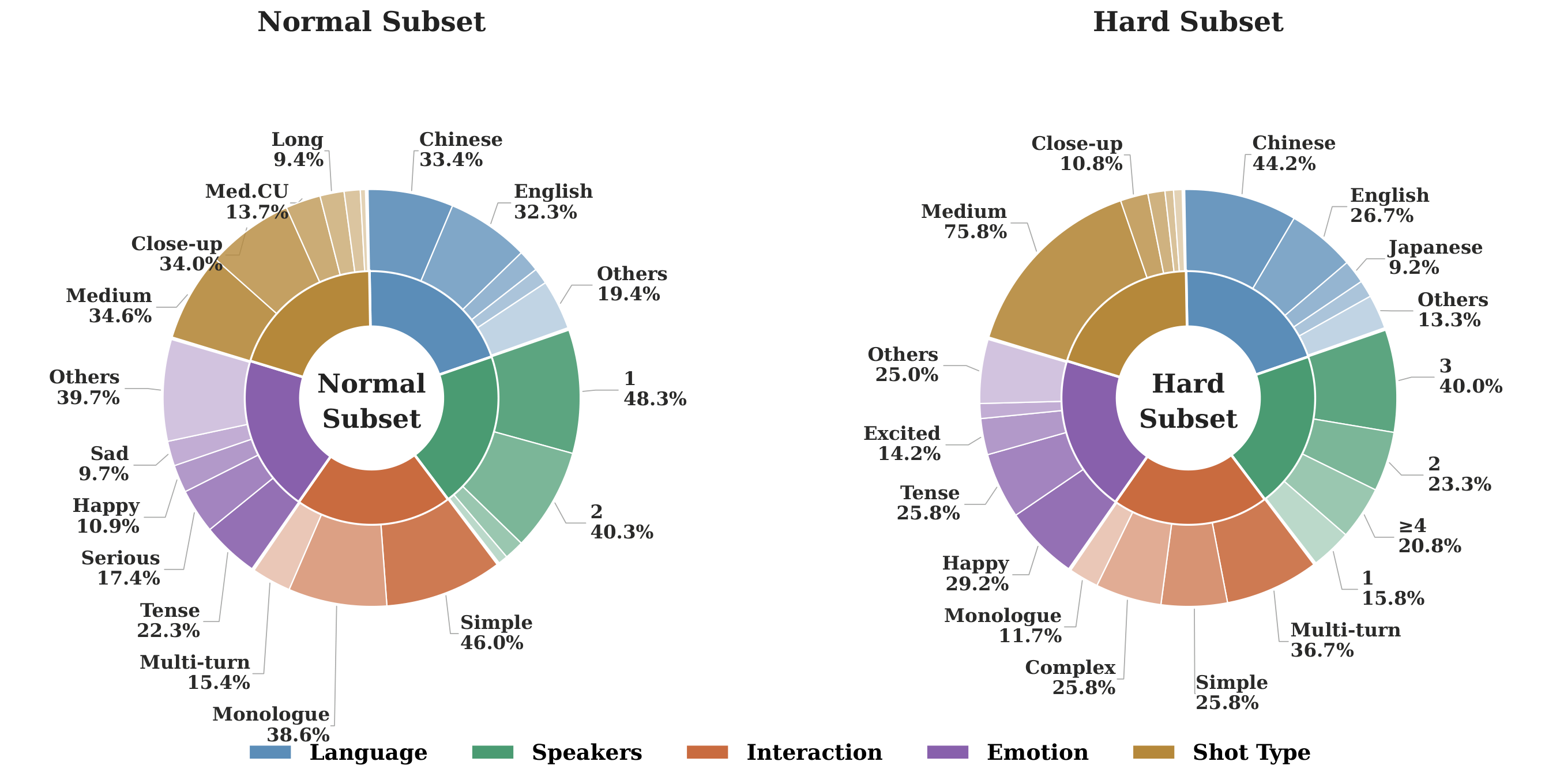
Figure 3. Data distribution of AVBench's normal and hard subsets. The multi-layer chart illustrates dataset diversity over key human-centric attributes including language, number of speakers, interaction complexity, emotional expression, and camera shot type. The hard subset contains a higher ratio of challenging scenarios to rigorously test fine-grained cross-modal alignment.
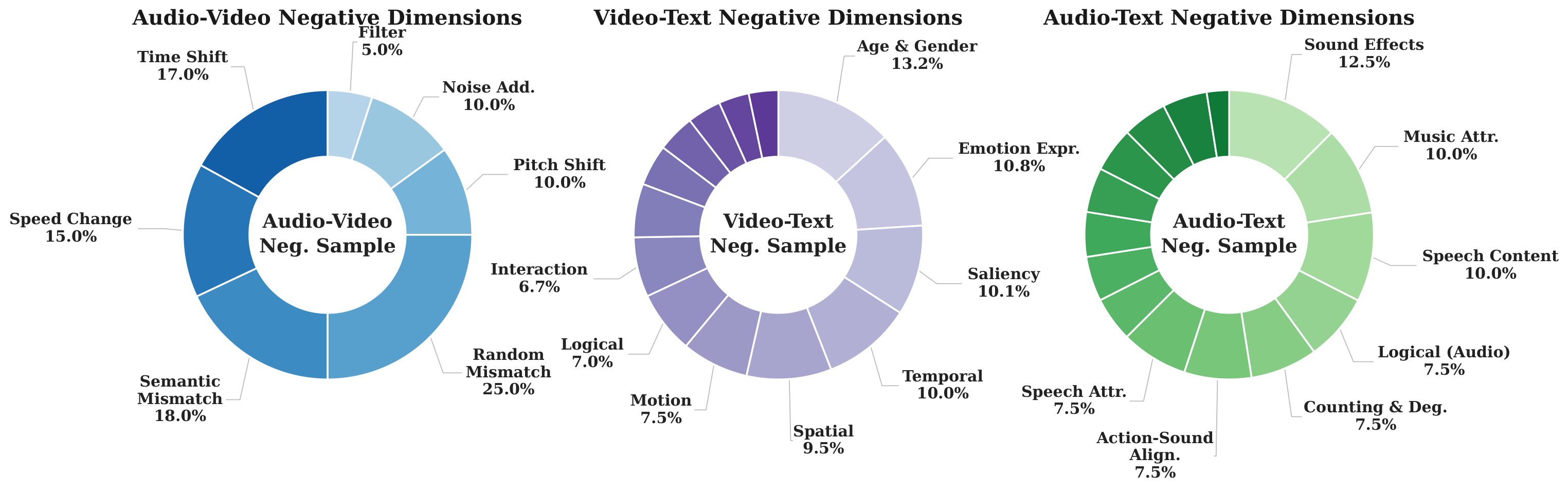
Figure 4. Taxonomy of multi-dimensional hard negatives in AVBench. The chart shows the comprehensive distribution of constructed negatives across major alignment axes. Rather than random perturbations, these dimensions are explicitly designed to target common T2AV failure modes, ensuring robust and fine-grained evaluation of cross-modal consistency.
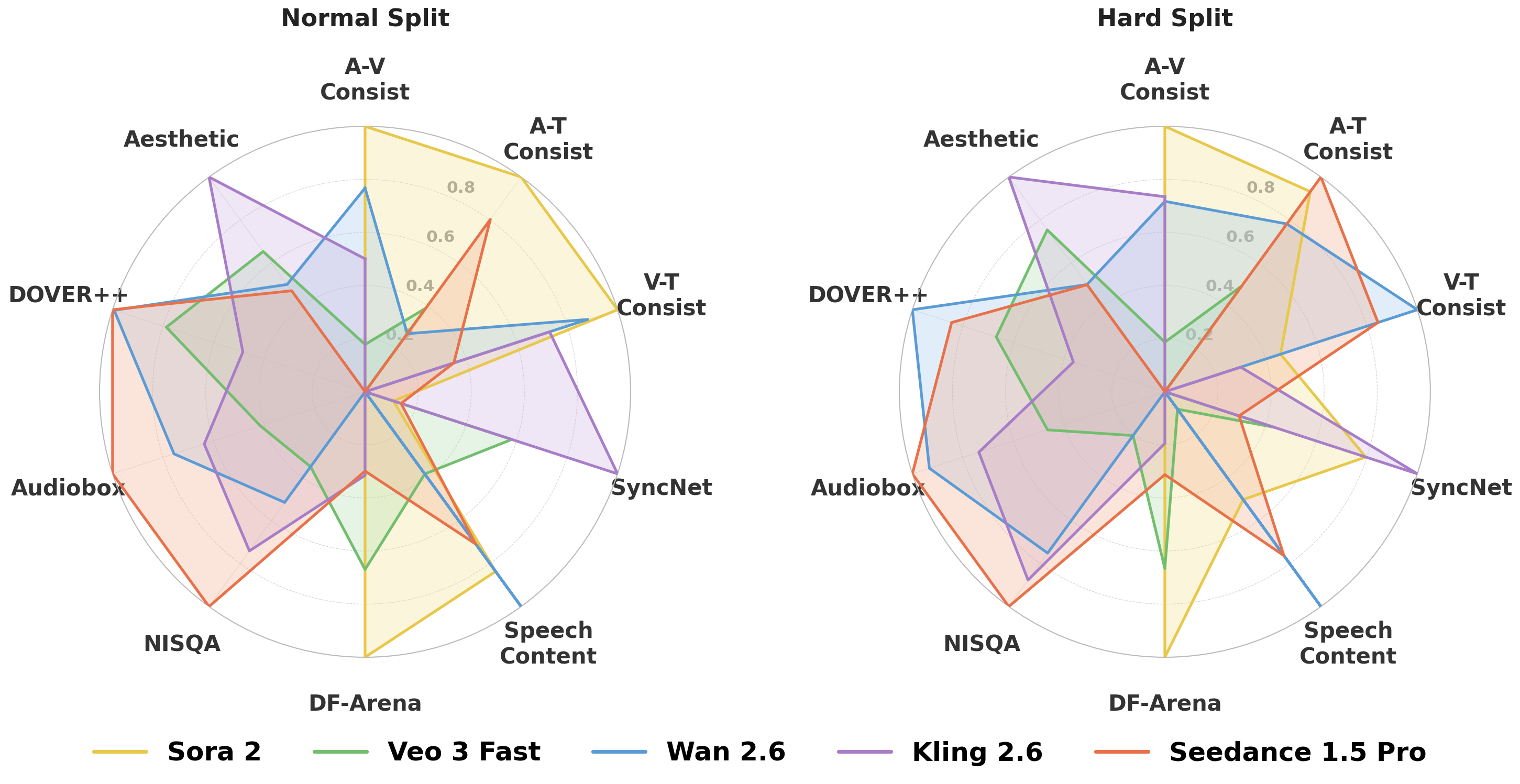
Figure 5. Holistic model performance. Radar comparison across AVBench dimensions reveals complementary strengths and weaknesses among representative T2AV systems, highlighting the persistent gap between technical quality and strict cross-modal instruction fidelity.
A 10-dimension protocol covers cross-modal alignment, speech content/realism, and audio-video perceptual quality in realistic human scenes.
Dedicated AV/AT/VT evaluators are trained on large-scale hard negatives, greatly improving sensitivity to subtle semantic and temporal mismatches.
A Normal/Hard hierarchical split exposes robustness limits, and evaluator outputs align well with human preference annotations.
AVBench evaluates 10 dimensions. Each dimension is paired with a concrete evaluation method for reproducible scoring.
Specialized SFT AV evaluator estimates audio-video semantic and temporal alignment via confidence-normalized Yes/No scoring.
Method: SFT AV EvaluatorSpecialized SFT AT evaluator measures whether generated audio faithfully matches prompt semantics and intent.
Method: SFT AT EvaluatorSpecialized SFT VT evaluator checks visual adherence to textual instructions under fine-grained human-centric conditions.
Method: SFT VT EvaluatorSyncNet-based alignment confidence and temporal offset analysis quantify speech-mouth synchronization fidelity.
Method: SyncNet / LatentSyncWhisper transcription with completeness, lexical accuracy, and hallucination penalty composes final speech-content score.
Method: Whisper-based ScoringDF-Arena discriminator evaluates naturalness and authenticity of synthesized voices against real human speech priors.
Method: DF-Arena DiscriminatorNISQAv2 MOS prediction provides perceptual audio-quality estimation across speech and environmental sounds.
Method: NISQAv2 MOSAudiobox aesthetic sub-scores are aggregated to reflect production quality, usefulness, and listening experience.
Method: Audiobox AestheticsDOVER++ evaluates technical visual fidelity and structural stability from a multi-perspective quality assessment view.
Method: DOVER++LAION-based aesthetic predictor scores overall visual composition and high-level perceptual appeal.
Method: LAION Aesthetic PredictorQuantitative results on AVBench Normal and Hard splits.
| Model | AV | AT | VT | SyncNet | SC | DF-Arena | NISQA | Audiobox | DOVER++ | Aesthetic |
|---|---|---|---|---|---|---|---|---|---|---|
| Sora 2 | 0.8713 | 0.8675 | 0.7599 | 4.9057 | 87.8391 | 0.4328 | 2.3784 | 3.1759 | 60.0125 | 4.0704 |
| Veo 3 Fast | 0.6924 | 0.8300 | 0.7235 | 6.5943 | 77.4950 | 0.3043 | 2.8191 | 3.5877 | 69.2275 | 4.9967 |
| Wan 2.6 | 0.8207 | 0.8227 | 0.7556 | 4.5016 | 91.5568 | 0.0441 | 3.0289 | 3.9271 | 71.6473 | 4.7790 |
| Kling 2.6 | 0.7626 | 0.8061 | 0.7501 | 8.1027 | 68.7844 | 0.1665 | 3.3141 | 3.8082 | 65.6786 | 5.4885 |
| Seedance 1.5 Pro | 0.6536 | 0.8554 | 0.7363 | 5.0146 | 84.9268 | 0.1602 | 3.6411 | 4.1686 | 71.7205 | 4.7373 |
| Model | AV | AT | VT | SyncNet | SC | DF-Arena | NISQA | Audiobox | DOVER++ | Aesthetic |
|---|---|---|---|---|---|---|---|---|---|---|
| Sora 2 | 0.9320 | 0.8575 | 0.7190 | 3.7932 | 76.7905 | 0.5498 | 2.0564 | 3.1339 | 58.1538 | 4.0434 |
| Veo 3 Fast | 0.7766 | 0.8117 | 0.6943 | 3.4535 | 70.3144 | 0.3827 | 2.3321 | 3.6113 | 67.0833 | 5.1438 |
| Wan 2.6 | 0.8780 | 0.8418 | 0.7482 | 3.0488 | 84.4512 | 0.0498 | 3.0726 | 4.0924 | 71.5229 | 4.7721 |
| Kling 2.6 | 0.8813 | 0.7602 | 0.7105 | 3.9844 | 69.0691 | 0.1469 | 3.2425 | 3.8912 | 62.9994 | 5.5033 |
| Seedance 1.5 Pro | 0.7409 | 0.8646 | 0.7398 | 3.3239 | 80.8029 | 0.2059 | 3.4093 | 4.1618 | 69.4430 | 4.7707 |
@misc{yang2026avbenchhumanalignedautomatedevaluation,
title={AVBench: Human-Aligned and Automated Evaluation Benchmark for Audio-Video Generative Models},
author={Jialiang Yang and Bin Xia and Ruihang Chu and Dingdong Wang and Wanke Xia and Zhun Mou and Tianyang Zhong and Yiting Zhao and Wenming Yang},
year={2026},
eprint={2605.24652},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2605.24652},
}